An Overview of Large-Scale Data Storage Architectures
Table of Contents
Abstract
Today, we begin a new journey to learn about the data lakehouse—especially how to store, process, and analyze large-scale data in in today’s data-driven world. We will start with the most fundamental concepts to build a solid understanding, then gradually move toward more advanced topics. Our two goals are simple: to understand the data lakehouse clearly, and to apply that knowledge effectively in our daily work.
Let’s get started
First, we need to clearly understand the problem. Then, we will explore and review the existing approaches to address it. Finally, we will select one approach for in-depth analysis and hands-on experimentation.
Problems
Today, data is fragmented and does not follow common standards. Data is often scattered, duplicated, and inconsistent across different systems. Many systems use local databases that are not synchronized, which leads to poor data quality—especially when data is transferred and processed through multiple intermediate systems. These issues reduce the effectiveness of data analysis and data usage, particularly as the demand for analytics and data visualization continues to grow.
Problems with local data storage (AI-generated images)
Therefore, building a large-scale data storage system, such as Lakehouse, is necessary to standardize data, improve data quality, and create a strong foundation for data analytics, visualization, and future AI models.
So, the solution is
"Build once, scale anywhere"
Building a Data Lakehouse platform to merge all data sources into one single source of truth. This system ensures data is clean and consistent while reducing costs by using low-cost cloud storage. It provides a flexible foundation to support data reports, visualizations, and AI/ML applications.
Approach
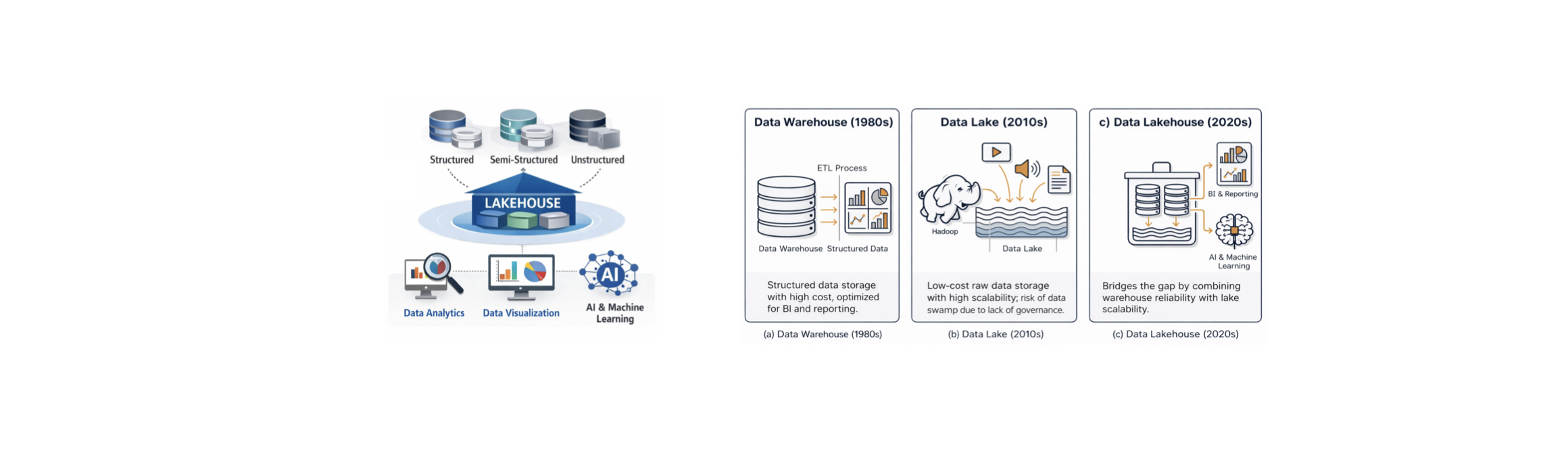
In the context of large-scale data storage, Data Warehouses, Data Lakes, and Data Lakehouses are fundamental concepts that must be considered. Each architecture reflects a distinct approach to data organization, processing, and usage, shaped by the growing volume, variety, and velocity of modern data.
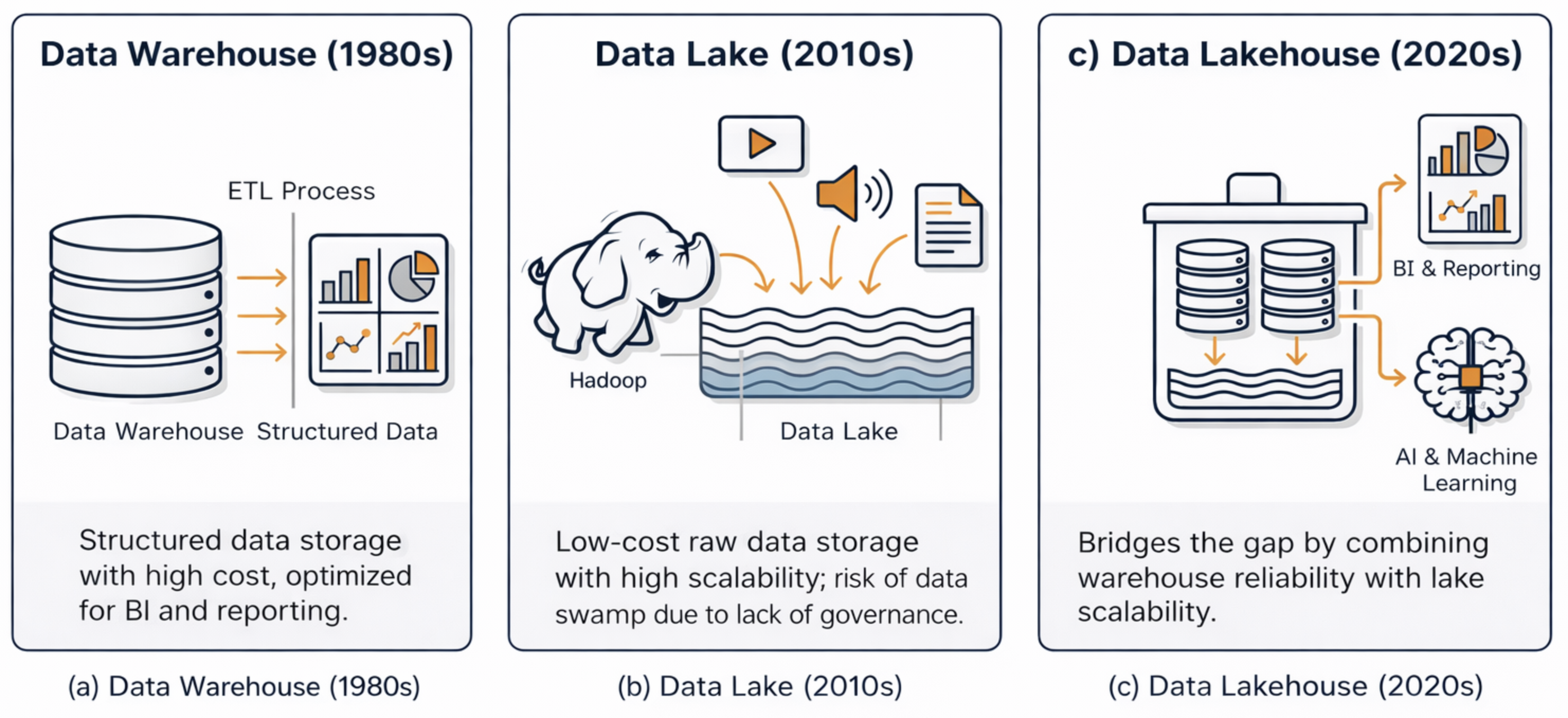
Evolution of large-scale data storage architectures from Data Warehouse to Data Lake and Data Lakehouse. (AI-generated images)
-
Data Warehouse:
Structured datastorage with high cost, optimized for BI and reporting. -
Data Lake:
Low-cost raw data storage with high scalability, risk of data swamp due to lack of governance.
-
Data Lakehouse:
Bridges the gap by combining warehouse reliability with lake scalability.
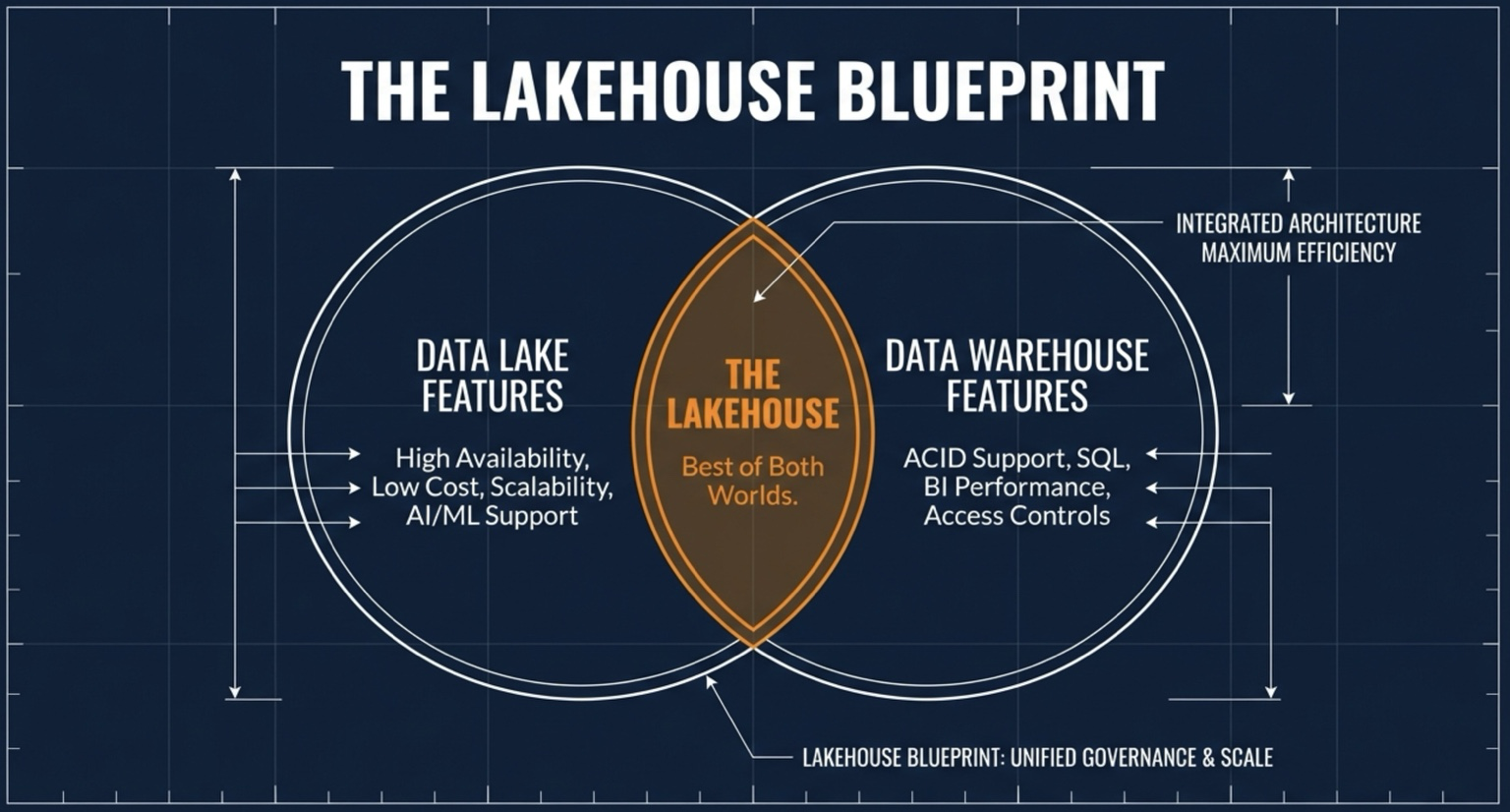
The Modern Data Lakehouse (AI-generated images)
The key lies in Open Table Formats
To effectively exploit data, we must first understand where the data is stored and how it is organized. Open Table Formats standardize the organization of both data and metadata using open specifications, enabling data stored in a Data Lake to be accessed and utilized in a database-like manner.
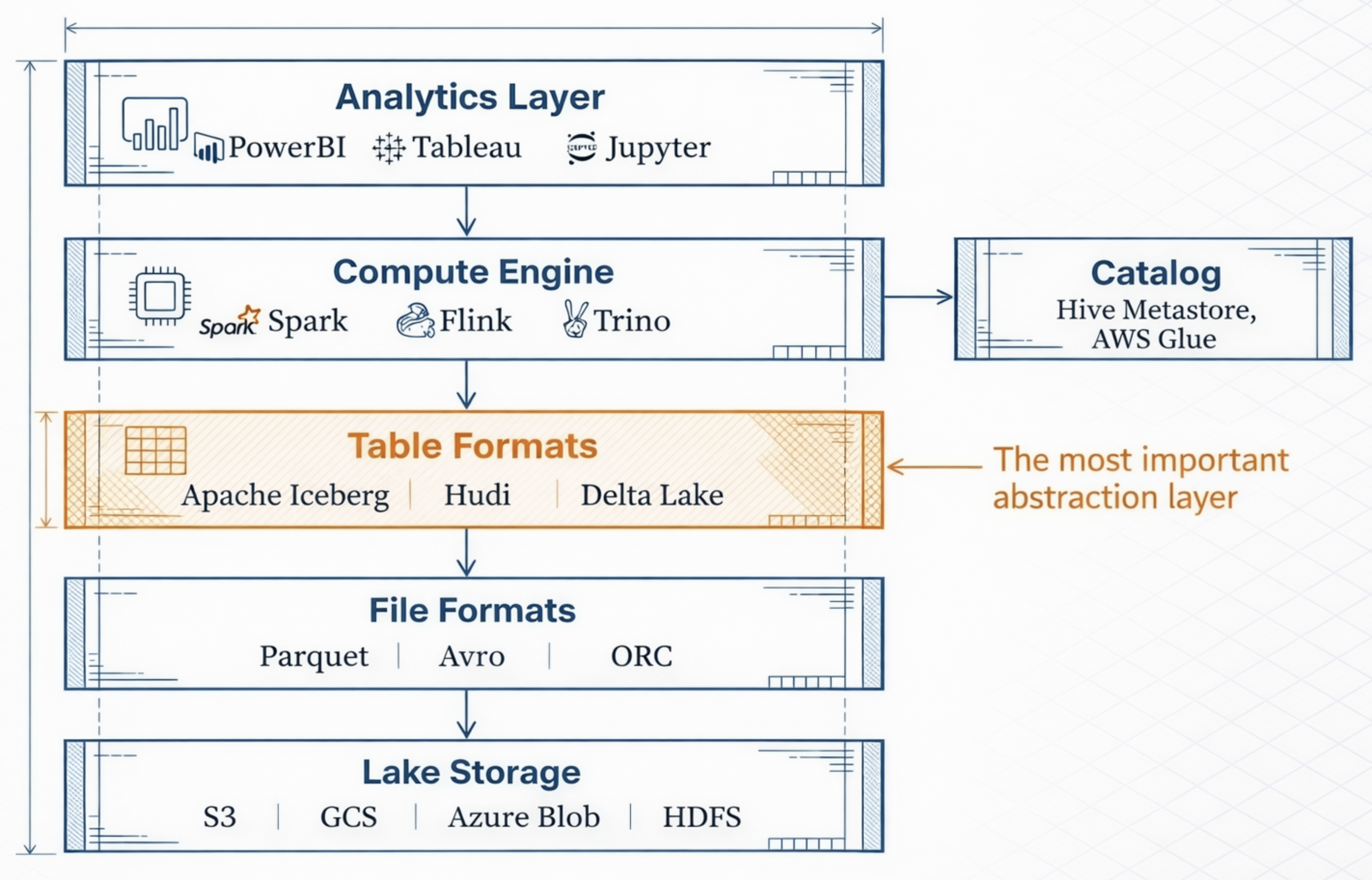
Data Lakehouse Layers (AI-generated images)
As a result, Open Table Formats (OTF) act as the “key” that transforms traditionally static Data Lakes into flexible, well-governed systems—providing consistency, scalability, and performance comparable to traditional database systems.
-
Traditional Data Lakes often fail because they are just collections of files without organization, leading to “data swamps”. Open Table Formats solve this by adding a transactional metadata layer on top of raw storage. This layer defines how a collection of files is managed and presented as a single table, allowing the system to track exactly which data belongs to which version.
-
Knowing Where Data Lives through Catalogs: To exploit data effectively, the system must know its exact location and state. Data Catalogs (such as Project Nessie, AWS Glue, or Hive Metastore) act as the “single source of truth” by providing a pointer to the latest metadata file. This metadata file contains a map of all physical data files, their schemas, and partitions, ensuring that every query engine sees the most current and consistent version of the data
-
Turning a Data Lake into a Database: By organizing data and metadata according to open standards, a Data Lake gains powerful database-like features:
• ACID Transactions: Ensures that data is never corrupted during concurrent reads and writes.
• Schema Evolution: Allows you to change table structures (adding or renaming columns) without rewriting the entire dataset.
• Time Travel: Enables users to query historical versions of data for auditing or debugging.
• High Performance: Uses file-level statistics (min/max values) to “skip” irrelevant data, making queries as fast as a traditional data warehous
Open Table Formats
This approach organizes data and metadata using open standards, allowing data stored in a Data Lake to be queried and managed like a traditional database. Today, this capability is enabled by three major open table formats: Delta Lake, Apache Iceberg, and Apache Hudi.
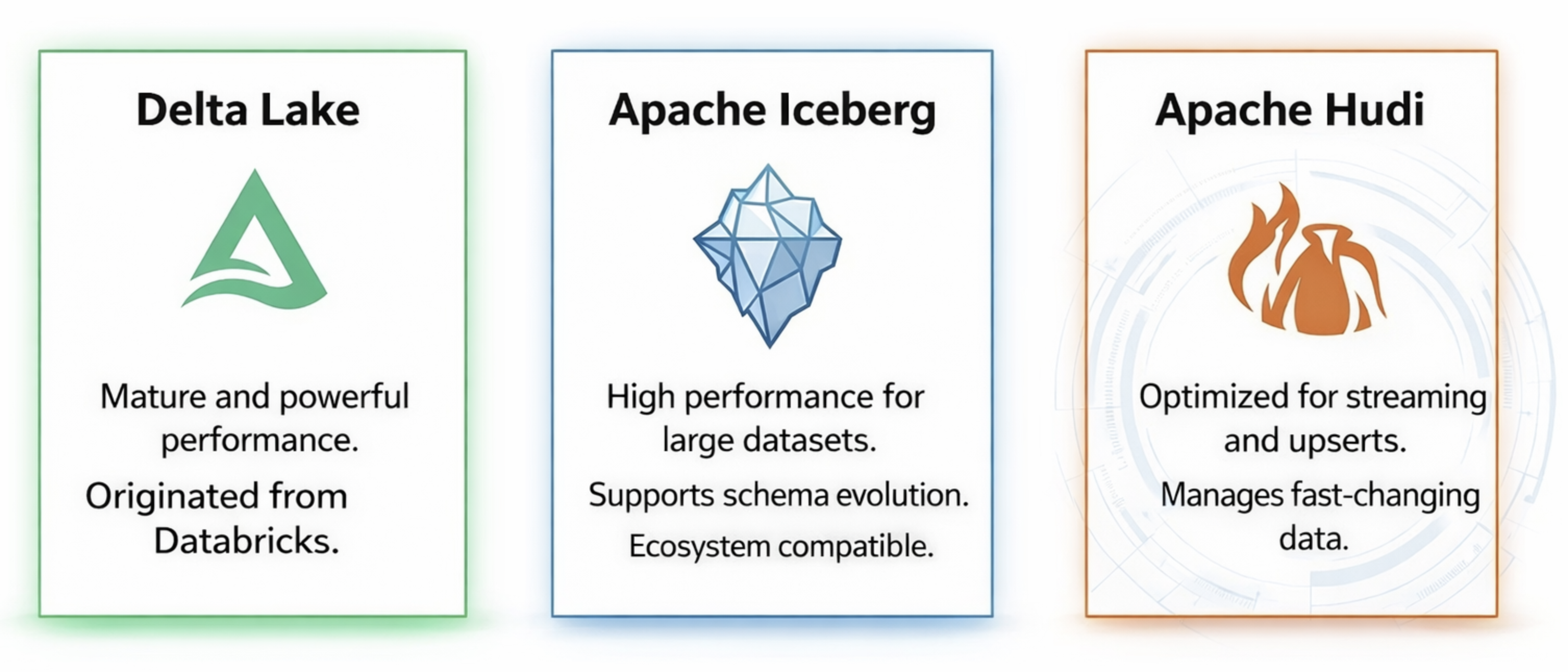
Open Table Formats (AI-generated images)
Delta Lake
Created by Databricks. Delta Lake was developed by Databricks, the company behind Apache Spark.
-
Simple and clear transaction log (_delta_log): It uses a simple transaction log based on JSON and Parquet files, making it easy to understand, debug, and manage.
-
Best integration with Spark: Delta Lake is natively designed for Apache Spark and works seamlessly with Spark SQL and Spark Streaming.
Apache Iceberg
- A truly open standard, engine-agnostic design: Designed to work independently of any specific compute engine.
- Snapshot-based metadata: Uses snapshot-based metadata to track table changes and enable time travel.
Apache Hudi
- Designed for streaming and upserts: Built to handle continuous data ingestion and update workloads.
- Strong support for record-level updates: Efficiently updates individual records without rewriting entire files.
Experimental Study
Based on the paper Data Lakehouse: A Survey and Experimental Study (Information Systems 127 (2025) 102460) by Ahmed A. Harby and Farhana Zulkernine, the authors compare and analyze three data platforms: Data Lake, Data Warehouse, and Data Lakehouse. The comparison is conducted using a storage system built on popular open-source technologies and a dataset from the Internet Movie Database (IMDb) containing 50,000 movies.
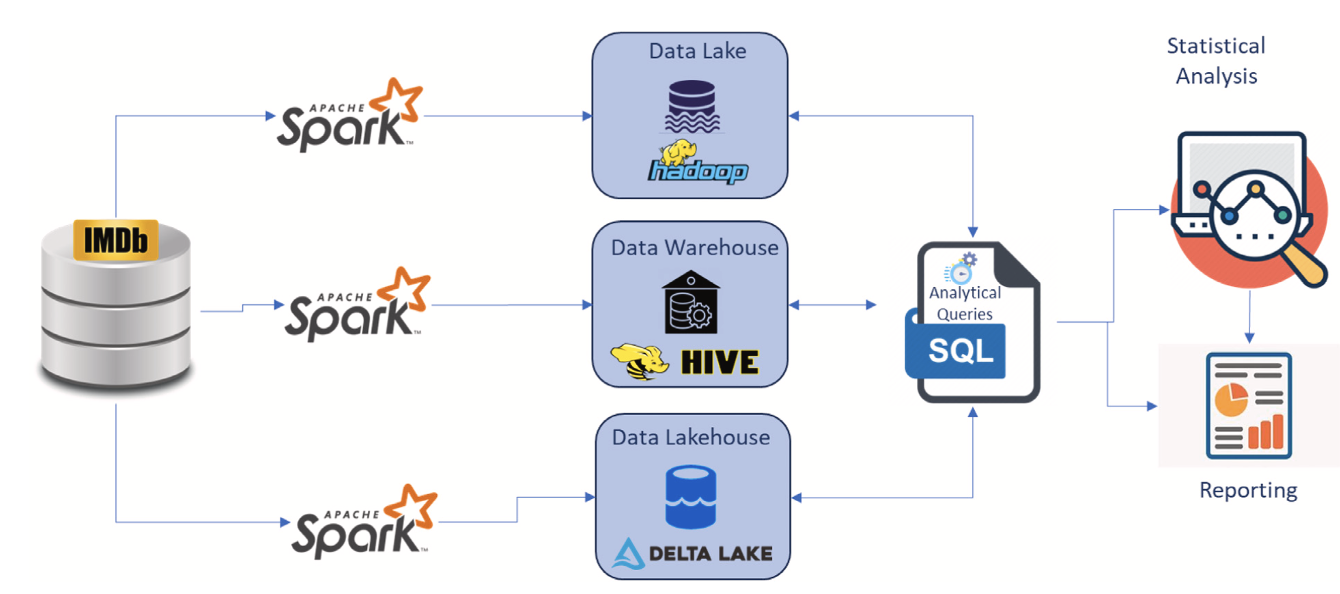
Data Lakehouse: A survey and experimental study (Information Systems 127 (2025) 102460) Ahmed A. Harby, Farhana Zulkerninea
Data Lakehouse: A survey and experimental study (Information Systems 127 (2025) 102460) Ahmed A. Harby, Farhana Zulkerninea
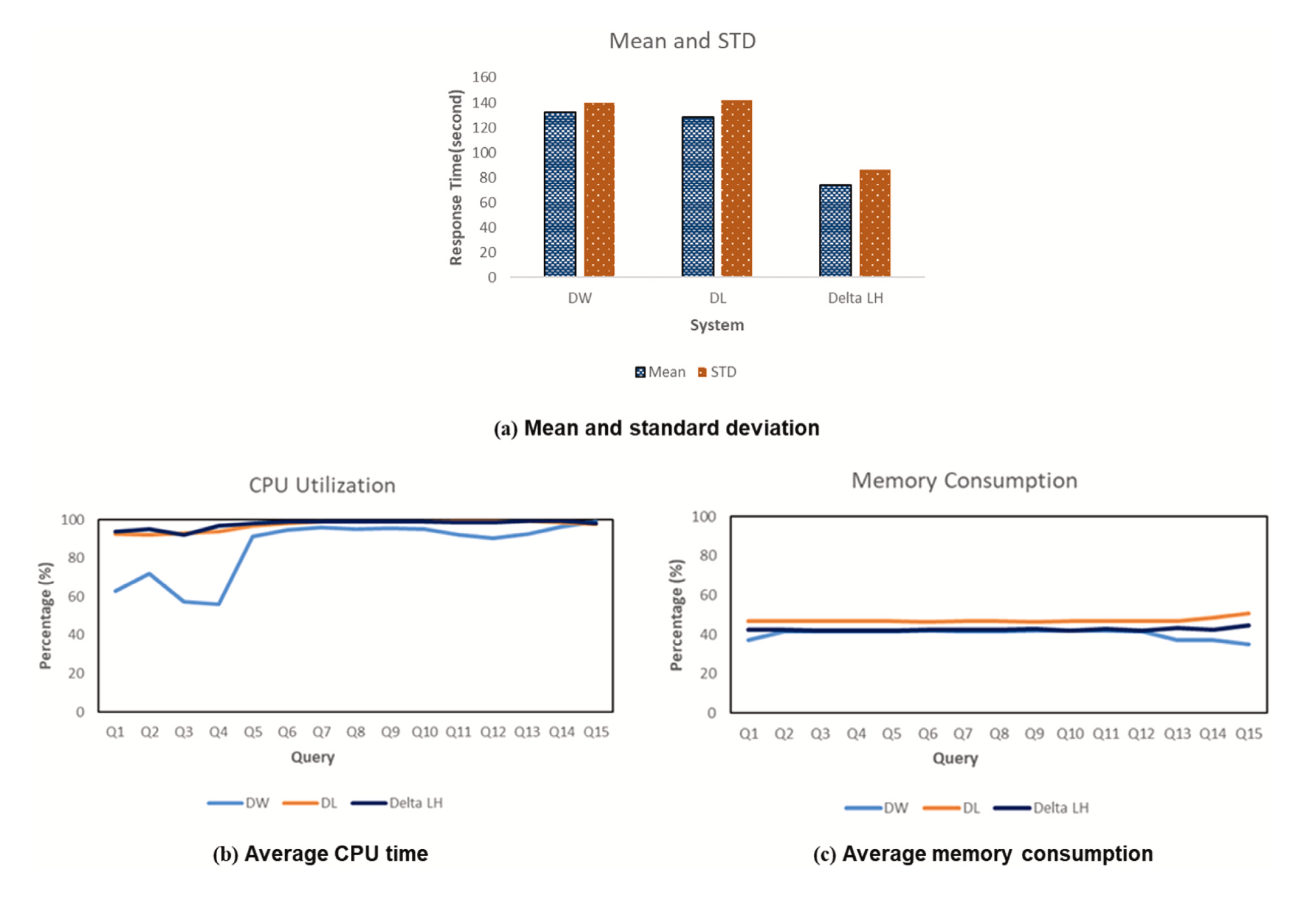
Data Lakehouse: A survey and experimental study (Information Systems 127 (2025) 102460) Ahmed A. Harby, Farhana Zulkerninea
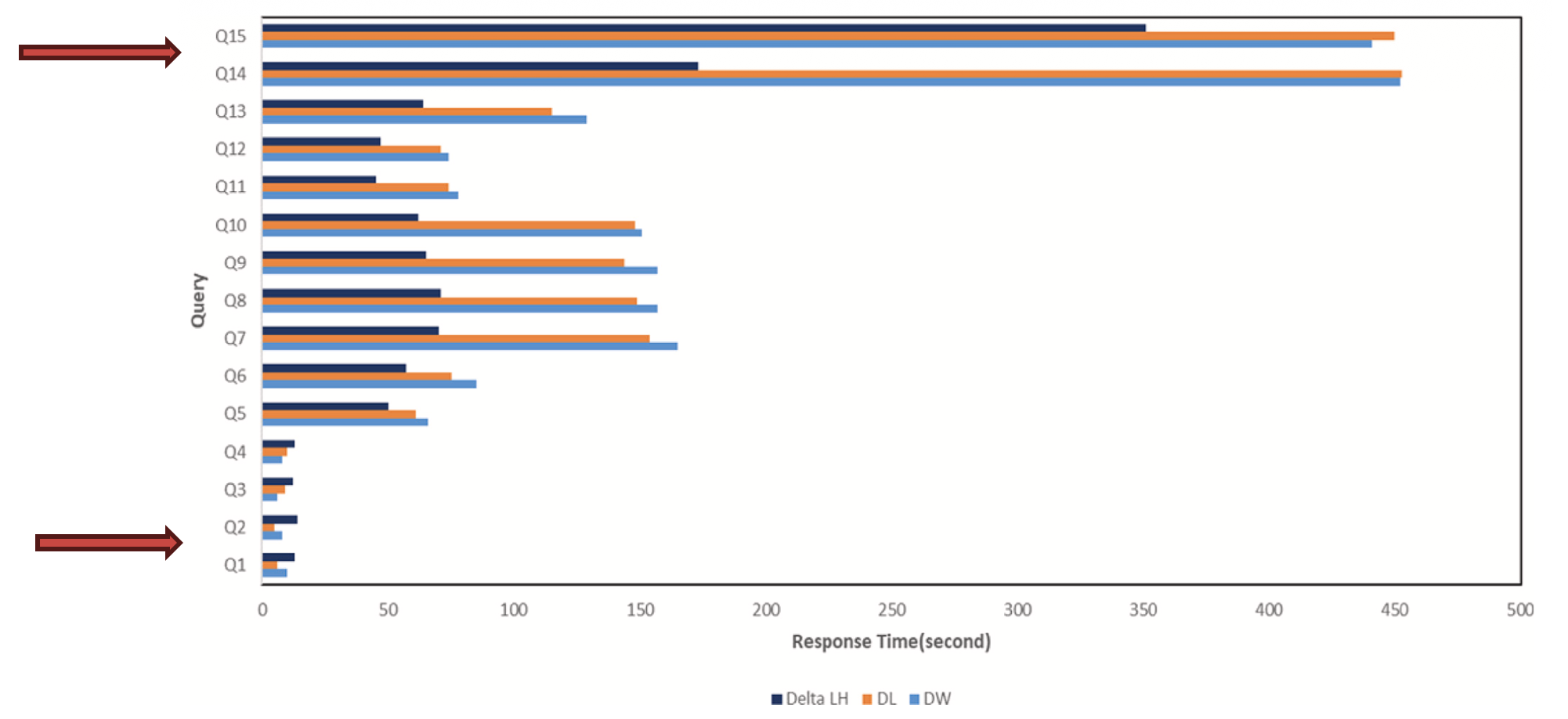
- Response time: Delta Lakehouse has slower response times for simple queries because of metadata management and consistency overhead. However, for complex queries (Q5–Q15), Delta Lakehouse delivers much better performance and scalability.
- Advanced features: Delta Lakehouse supports capabilities that traditional Data Lakes and Data Warehouses do not, such as Time Travel (querying data at a past point in time) and Schema Evolution (changing the table schema without rewriting existing data)
- Resource consumption: Delta Lakehouse uses more CPU on average than Hive due to its automated metadata management layer, but it uses memory more efficiently thanks to Optimistic Concurrency Control.
What’s Next?
Now we have a general understanding of the system.
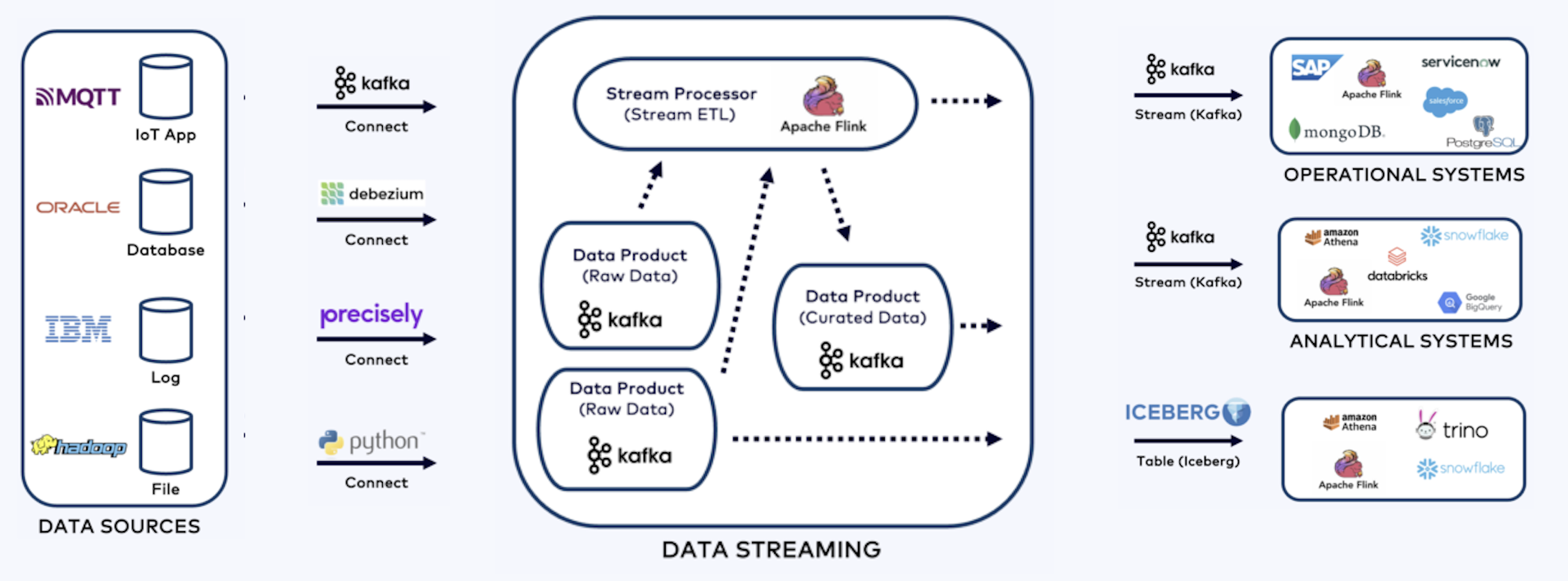
Shift Left Architecture
Next, we will build an end-to-end prototype, starting with the basic flows. This helps us understand how everything works and see the overall structure.
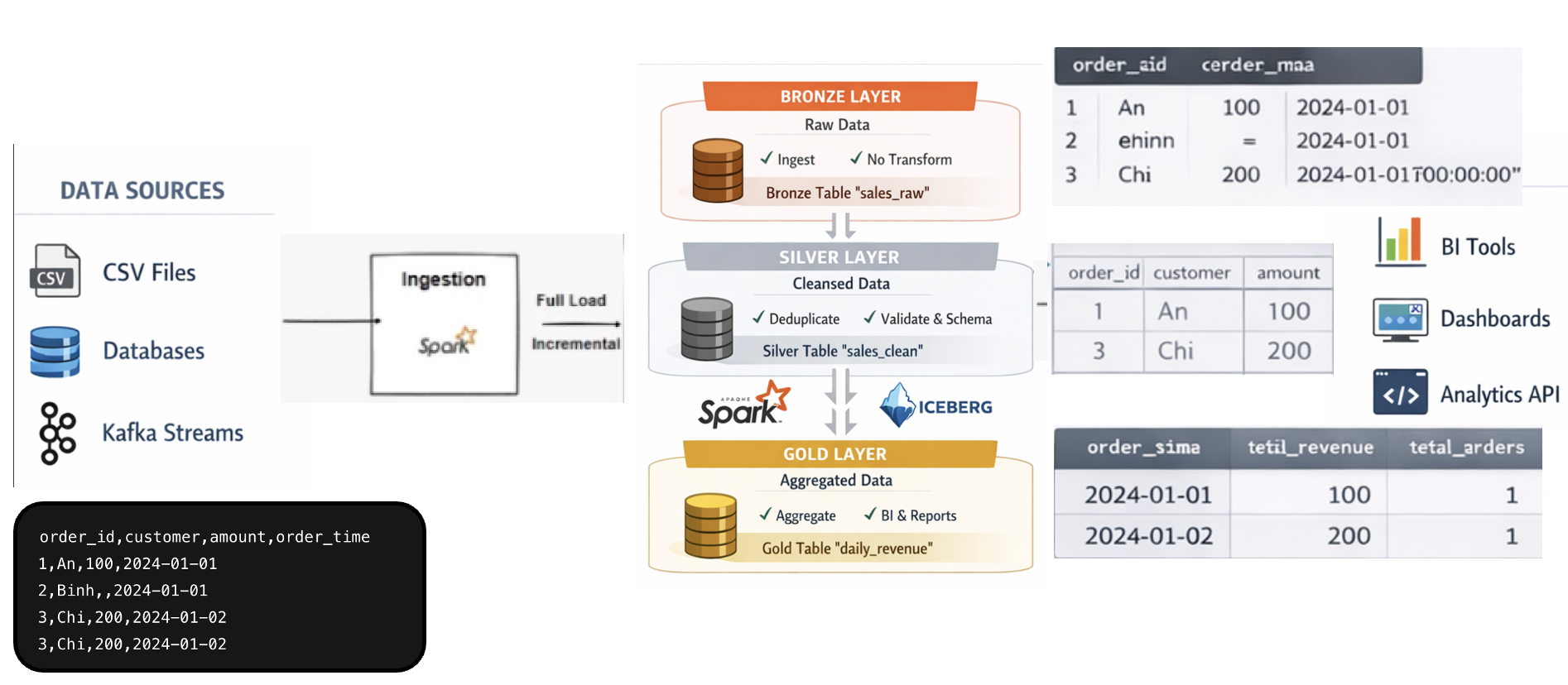
Build end-to-end prototype
Wow, that’s amazing. See you soon!
