Predictive Modelling of Diseases Based on a Network and Machine Learning Approach (Book of Abstracts - My Paper)
Table of Contents
At the end of 2022. I obtained a paper at the ACIIDS 2022 conference. So I want to share with you about this. I hope that it is a motivation to make the new goals for the next year.
BOOK OF ABSTRACTS
Abstract
Chronic diseases have become the first prioritized concern of the health industry, so understanding the disease progression is necessary for predicting, planning and preparing resources to prevent and cure the diseases most effectively. Basing on patients’ medical history, this research analyzes and builds disease network to exploit hidden information showing the disease relations and progressions, applys machine learning models to assess the risks of morbidity and predicts the risk of contracting cardiovascular diseases (CVD) in patients with type-2 diabetes (T2D). The research data includes 249,809 medical histories of 65,337 patients in Ho Chi Minh City, Vietnam. The accuracies of the four prediction models (SVM, DT, RF and KNN) range from 78% to 80%. The predicted data can be used promisingly as a reference for medical specialists to provide effective healthcare guidance to patients as well as for healthcare service providers to use their data effectively and enhance their service quality.
Introduction
World Health Organization (WHO) defines chronic diseases as non communicable diseases (NCDs), which are not transmissible directly from person to person and are associated to long duration and slow progression. They have become the leading cause of fatality in most countries. According to WHO, 41 million people die from an NCD annually, which accounts for 77% of all deaths worldwide. Moreover, almost 50% out of these deaths are premature deaths (under 70 years old) and this percentage is growing. Because most NCD patients are still in their working age, chronic diseases reduce labor productivity and increase pressure on the medical system, resulting in considerable financial burdens to the economy of countries, especially low- and middle-income ones. Among four main types of NCDs, Type 2 diabetes is the most dangerous because it has the highest morbidity rate in the world. In fact, it is the top cause of fatality and it increases the risk of contracting other chronic diseases such as cardiovascular diseases.
Understanding the progression of chronic diseases and making predictions relating to them can provide im- portant information useful for the prevention and management of the diseases. Thus, many models have been proposed to forecast the morbidity risk of chronic diseases, which can be divided into two main approaches: (i) Traditional statistical approaches and (ii) Machine learning and data mining approaches. However, both methods require a very big and full administrative data set with a great number of medical records, which are extremely difficult to collect because patients’ medical data are usually privately secured, discrete and unshareable. Besides, there exist some limitations in the exploitation of the relations among diseases and the progression of them. Also, the above approaches are very different in the method of implementation.
Therefore, in the research scope, this study proposes a new method by widening and combining the above two approaches in order to build a risk prediction model for chronic diseases. Specifically, this study will predict the morbidity risk of cardiovascular diseases in type 2 diabetes patients.
State of the art
The rise of chronic diseases increases the health and financial burden. Therefore, there have been many studies on the improvement of patients’ health through prevention, early identification, and proper treatment. However, most approaches have not shown the progression and association between diseases. They also have many limitations in accessing data because the patient’s health data is often confidential, discrete, and not shared. For example, some regression models are not suitable because medical data has too many objects such as patients, diseases, doctors, drugs, etc. Therefore, model building is often complicated because there are many independent variables.
Although machine learning methods are rich in techniques and tools, they do not show the necessary time and relationship factors in disease prediction. Models based on network analysis are often developed to find hidden patterns and relationships between objects. However, in the medical field, clinical diagnoses are often based on disease factors such as medical history, demographic information, vital signs, etc. These factors can also have a major influence on patient outcomes. In most cases, this information has not been exploited. Therefore, this study proposes a new approach by extending and combining existing methods, with the overall goal of focusing on understanding the progression of chronic disease through disease networks and identifying which patients are at risk of other chronic diseases in the future by applying machine learning algorithms to develop disease prediction models
Original contribution
-
Instead of approaching the traditional statistical methods to build model, the study applies graph theory and network analysis to develop a disease network, and then applies machine learning methods to build a disease prediction model basing on the data extracted from the disease network.
-
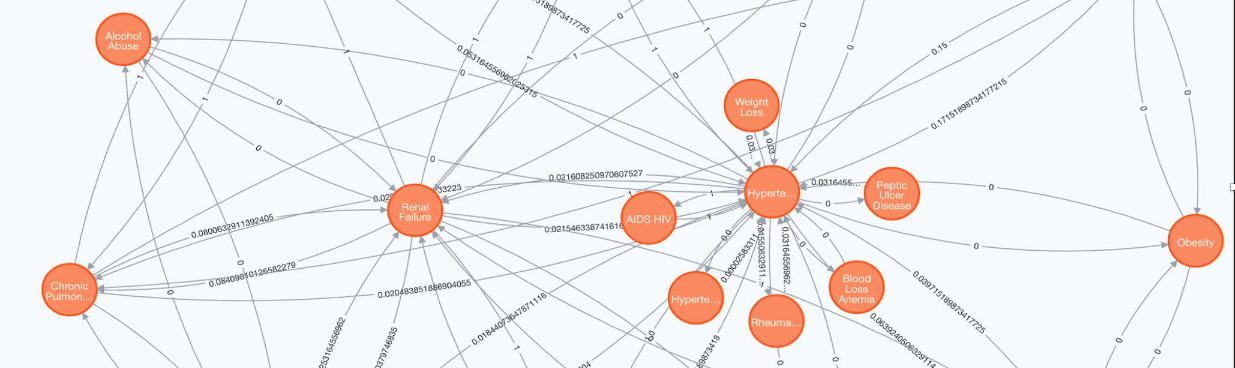
The disease network created in this study presents the relations and the progressions of chronic disease comorbidities, as well as providing a simple way to visualize the health trajectory of chronic disease patients.
Methodology
The study is divided into two main parts, (i) understanding disease progression through network analysis approach and (ii) developing disease prediction models through machine learning algorithms. To build the disease network, two cohorts (the group of patients with T2D only and the group of patients with both T2D and CVD) were ag- gregated from their medical history to create two corresponding base disease networks. The final disease network is generated by aggregating the above two base networks. This disease network provides detailed information on the progression and relation of CVD in patients with T2D. Based on these insights, the development of a disease prediction model was also the second goal of this study. To develop the model, the study has extracted five fea- tures, three of which are from the disease network (node, edge and cluster) and the other two are from the data set. (gender and age). These features are then used to develop predictive models of CVD risk in patients with T2D.
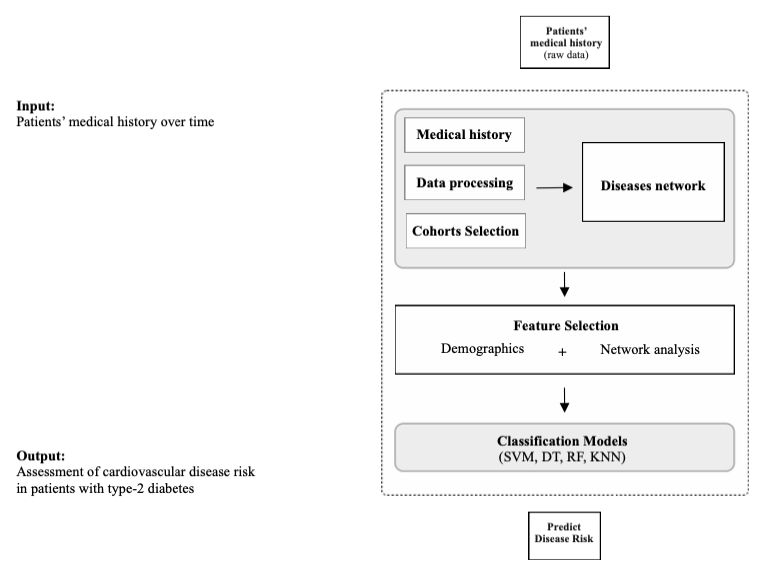
Overview of prediction framework
Results
The built disease network includes 19 chronic diseases and the edges represent disease progression. Four machine learning algorithms are used: SVM, DT, RF and KNN. Overall, the accuracies of the four models are almost similar. However, the study found that the predictive model based on SVM had the best accuracy of 80.02%, followed by the DT with an accuracy of 79.12%.
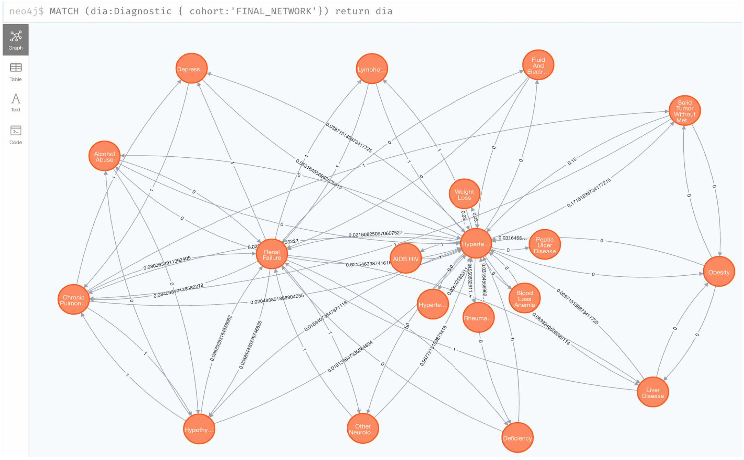
Disease network visualization

The performance of models
Evaluation
This study uses 249,809 medical histories of 65,337 patients in a hospital in Ho Chi Minh City. 65% of patients in each cohort were randomly selected to build a disease network. The remaining 35% was divided into two datasets: the training and the test datasets. With the training dataset, 10-fold cross-validation was used to train and test the model and the test dataset was used to evaluate the performance of the models. The study used a confusion matrix to calculate the common measures such as accuracy, precision, recall, F1 score and ROC curve to evaluate the efficiency. Despite using only the disease classification code combined with some other basic features (age and gender), the approach gives quite good accuracy. Therefore, this is expected to be a new development direction in the current context of very little and sparse medical data.
Conclusions
Disease prediction is an important research in the health industry and especially in preventive medicine. In the context of the rapid increase of chronic diseases, especially in low- or middle-income countries, and the increasing burden of disease due to population aging in many parts of the world, the results of disease prediction models are important inputs for planning and preparing resources for effective disease prevention. Moreover, this research could be useful to individuals and organizations in the healthcare field as it can help healthcare providers use their data more efficiently and improve their services.

DOI: https://doi.org/10.1007/978-981-19-8234-7_50
Posts in this Series
- Predictive Modelling of Diseases Based on a Network and Machine Learning Approach (Book of Abstracts - My Paper)
- Latex Take Notes
- Factorization Machines & Their Application on Huge Datasets Presentation
- FACTORIZATION MACHINES and THEIR APPLICATION on HUGE DATASETS
